Writing Substrate runtime migrations
Introduction
One of the defining features of Substrate based blockchains is the ability to perform forkless updates to it’s own runtime. This is made possible by the fact that the runtime, i.e. the state transition function, is a part of the overall blockchain state.
The upgrade itself is pushed as a transaction to the nodes participating in the consensus, and they can agree on it as part of the normal chain operation. Thus at some block, the definition of the state transition function changes, as depicted below [1]:
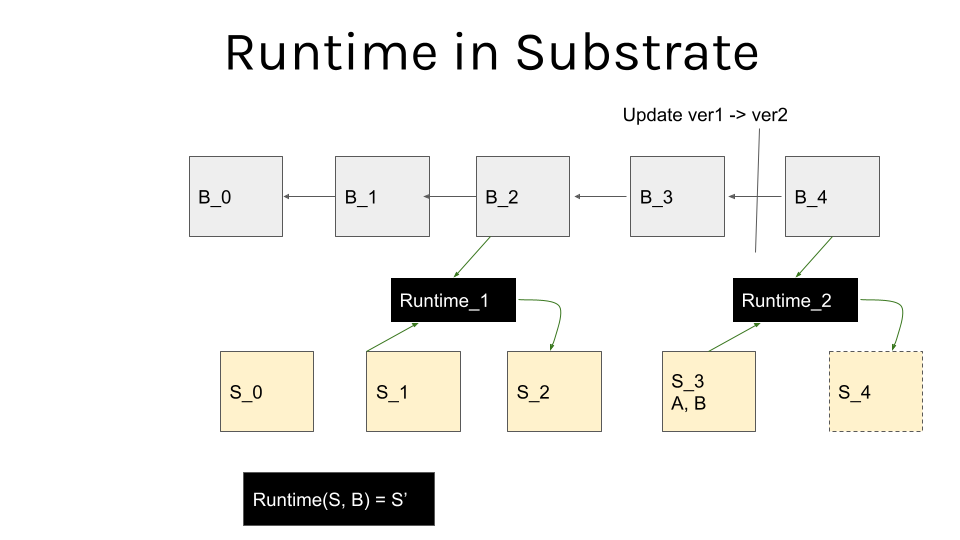
There are couple important differences between performing regular transactions and runtime updating ones, however for the purpose of this document one of the most critical ones is the fact that they are not additive, they can bring consensus breaking logic, thus it is important to version them accordingly.
NOTE
In order for the node to be able to select the appropriate runtime execution environment, Substarte uses a special RuntimeVersion struct. After the runtime is upgraded it’s WASM binary is stored as a part of the blockchain state (i.e. under a known storage key in the trie) and the runtime executor chooses between the native and WASM compiled runtime based on a set of rules. It is therefore paramount to increase the version of the runtime when introducing any changes, as it is the only mechanism at the executors disposal to be able to choose the updated one, else it will fall back to using the native runtime.
What are storage migrations and when do you need to write them?
The runtime logic changes can implicitly change the schema of the blockchain state. You can think of it as of schema changes in a regular, centralized storage, like a database - if the state does not conform to the logic, it will inevitably break. One example would be an update that expects a different type for a storage value: say i32 (signed integer) to u32 (unsigned integer).
This is when you will need to include a storage migration that transforms the state from the previous one into the one that the updated logic expects. In another words storage migrations are a special kind of one-time functions that allow to normalize the existing storage schema into an updated one.
Ordering of migrations
Substrate defines a strict order in which storage migrations are applied [2]. FRAME storage migrations will run in the following order (since this commit):
- Custom
on_runtime_upgrade frame_system::on_runtime_upgrade- All
on_runtime_upgradefunctions defined in all included pallets, in the reverse order of their declaration (as defined in theconstruct_runtime!macro)
Next in the execution order are these functions:
frame_system::initializeframe_system::on_initialize- All pallet
on_initializesin the reverse order of their declaration (as defined in theconstruct_runtime!macro)
As a runtime developer you will likely mostly deal with the FRAME (aka pallet) storage migrations.
These are implemented via the Hooks traits on_runtime_upgrade function, for example:
#[pallet::hooks]
impl<T: Config> Hooks<BlockNumberFor<T>> for Pallet<T> {
fn on_runtime_upgrade() -> frame_support::weights::Weight {
do_migrate::<T, Self>()
}
}
NOTE
Substrate documentation mentions OnRuntimeUpgrade as the go to trait for implementing migrations hooks here, however none of the pallets actually uses it, so this information is likely outdated.
Couple notes here:
Because of the ordering the on_runtime_upgrade function will be called before on_initialize initializes the runtime.
This means that many of the runtime state information will not be available to it, such as the currently block number or block local data.
The function returns the weight consumed by performing the runtime upgrade.
A natural question to ask is whether you can override the default migrations order, which might be needed in some complex scenarios. The answer is yes you can, via the so-called Custom on_runtime_upgrade which runs before any pallet specific migrations are run.
An example custom runtime upgrade that executes the balances pallet migration before the accounts migration:
mod custom_migration {
use super::*;
use frame_support::{traits::OnRuntimeUpgrade, weights::Weight};
use pallet_balances::migration::on_runtime_upgrade as balances_upgrade;
use frame_system::migration::migrate_accounts as accounts_upgrade;
pub struct Upgrade;
impl OnRuntimeUpgrade for Upgrade {
fn on_runtime_upgrade() -> Weight {
let mut weight = 0;
weight += balances_upgrade::<Runtime, pallet_balances::DefaultInstance>();
weight += accounts_upgrade::<Runtime>();
weight
}
}
}
/// Executive: handles dispatch to the various modules.
pub type Executive = frame_executive::Executive<Runtime, Block, frame_system::ChainContext<Runtime>, Runtime, AllModules, custom_migration::Upgrade>;
Writing migrations
Versioning
One crucial thing you need to have in mind when writing migrations in Substrate is that they have no rollback, thus you want to make sure the are correct and applied correctly.
First thing to do is to include storage version checks, that assure you are migration from the correct version and that the migration will execute only once.
StorageVersion is used to store a single u16 that defines the current on-chain version of the pallet.
Frame has a attribute macro for defining it, that creates a storage value under a :__STORAGE_VERSION__: key with the prefix being the pallet name:
#[pallet::pallet]
#[pallet::storage_version(STORAGE_VERSION)]
pub struct Pallet<T>(sp_std::marker::PhantomData<T>);
If your pallet does not define it, it’s version will default to 0u16. This struct has some other utility traits implemented, notably it differentiates between the on-chain storage version and the current pallets version. You can use that fact to write “guards” that assert when to apply a given migration, e.g.:
let on_chain_storage_version = <P as GetStorageVersion>::on_chain_storage_version();
let current_storage_version = <P as GetStorageVersion>::current_storage_version();
if on_chain_storage_version == 1 && current_storage_version == 2 {
/// migration logic
// update version
StorageVersion::new(2).put::<P>();
}
Notice how you, the pallet migration author are responsible for setting the correct storage version after the migration runs.
NOTE
Older Substrate versions (before this commit) used a different versioning scheme, based on a macro that pulled a semver from the pallets Cargo.toml file.
This is now deprecated, and if needed, you can apply the following one-time custom migration that migrates from PalletVersion to the StorageVersion.
pub struct MigratePalletVersionToStorageVersion;
impl OnRuntimeUpgrade for MigratePalletVersionToStorageVersion {
fn on_runtime_upgrade() -> frame_support::weights::Weight {
frame_support::migrations::migrate_from_pallet_version_to_storage_version::<AllPalletsWithSystem>(
&RocksDbWeight::get()
)
}
}
pub type Executive = frame_executive::Executive<
Runtime,
Block,
frame_system::ChainContext<Runtime>,
Runtime,
AllPallets,
MigratePalletVersionToStorageVersion
>;
Migrations mean transforming the data from the old to the new runtime perspective. That means you might have to include deprecated types as part of it. generate_storage_alias! macro is of great use here.
When it comes to all kinds of available data manipulations take a look at the StorageValue trait.
Including ample logging, that will help you find any problems as well as assert that the migration was applied successfully.
Testing migrations
You can and in fact you should test your migrations thoroughly, as you definitely do not want to end up with a corrupted storage. You should assert them both in a unit-test scenario as well as on a live data.
Unit tests
Unit tests could be as simple as:
- Populate the storage of a
new_test_extenvironment (see frame_support::migration::put_storage_value). - Run the migration function.
- Assert the correct shape of the new data.
Manual tests
Finally you can perform manual test on a live chain using a tool like fork-off-substrate to get a snapshot of a chain state and apply the upgrade extrinsic on it.
Executing migrations
Any migrations will be executed, in the order defined here, as part of a runtime upgrade procedure.
Rough steps are:
- Compile the updated wasm runtime binary
cargo build --release -p aleph-runtime
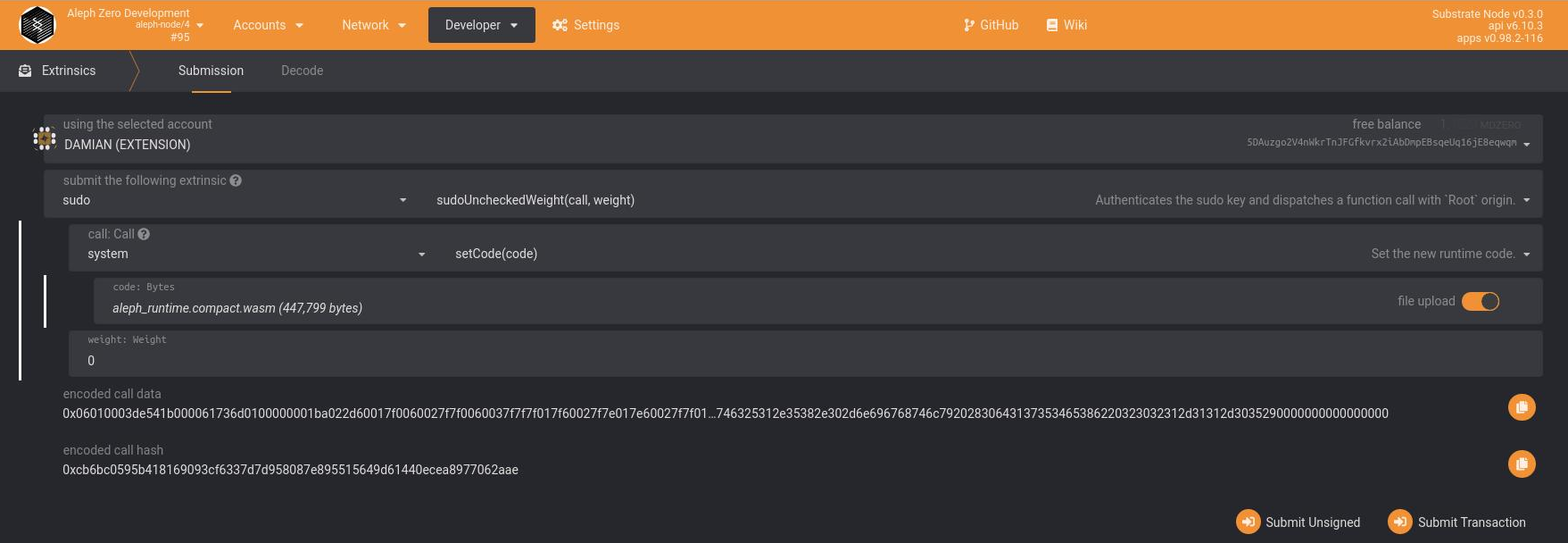
- execute the
setCodeextrinsic (signed by the sudo account):
Removing migrations
Substrate recommends removing the migrations from the on_runtime_upgrade hook in time for the next runtime upgrade, but leaving them along the pallet code for reference and documentation.
They also started using a E1-runtimemigration label to mark past PRs that contain runtime migrations.
Substrate version updates and FRAME migrations
If you are not a pallet author and are running migrations already included in the FRAME pallets you are still responsible for taking some care in applying them. There will always be some manual work necessary for any one of these cases.
At the very minimum you are responsible for checking the changelog for past migrations and applying them in the correct order.
Further reading
- https://github.com/apopiak/substrate-migrations
- Migrations Guide https://hackmd.io/BQt-gvEdT66Kbw0j5ySlWw
- https://docs.substrate.io/v3/runtime/upgrades/
- https://docs.substrate.io/how-to-guides/v3/storage-migrations/basics/
- Improve Migration Support: https://github.com/paritytech/substrate/issues/6482
- Migration examples from Substrate repository https://github.com/paritytech/substrate/issues?q=label%3AE1-runtimemigration
1: Image courtesy of DamianStraszak
2: Taken from https://hackmd.io/BQt-gvEdT66Kbw0j5ySlWw