Spread dataviz software
Intro
As a student in the evolutionary and computational virology group led by professor Philippe Lemey and as part of my thesis on Continuous-time Markov Chain Models I wrote SpreaD3, a small software package for visualizing how viruses spread in time and space.
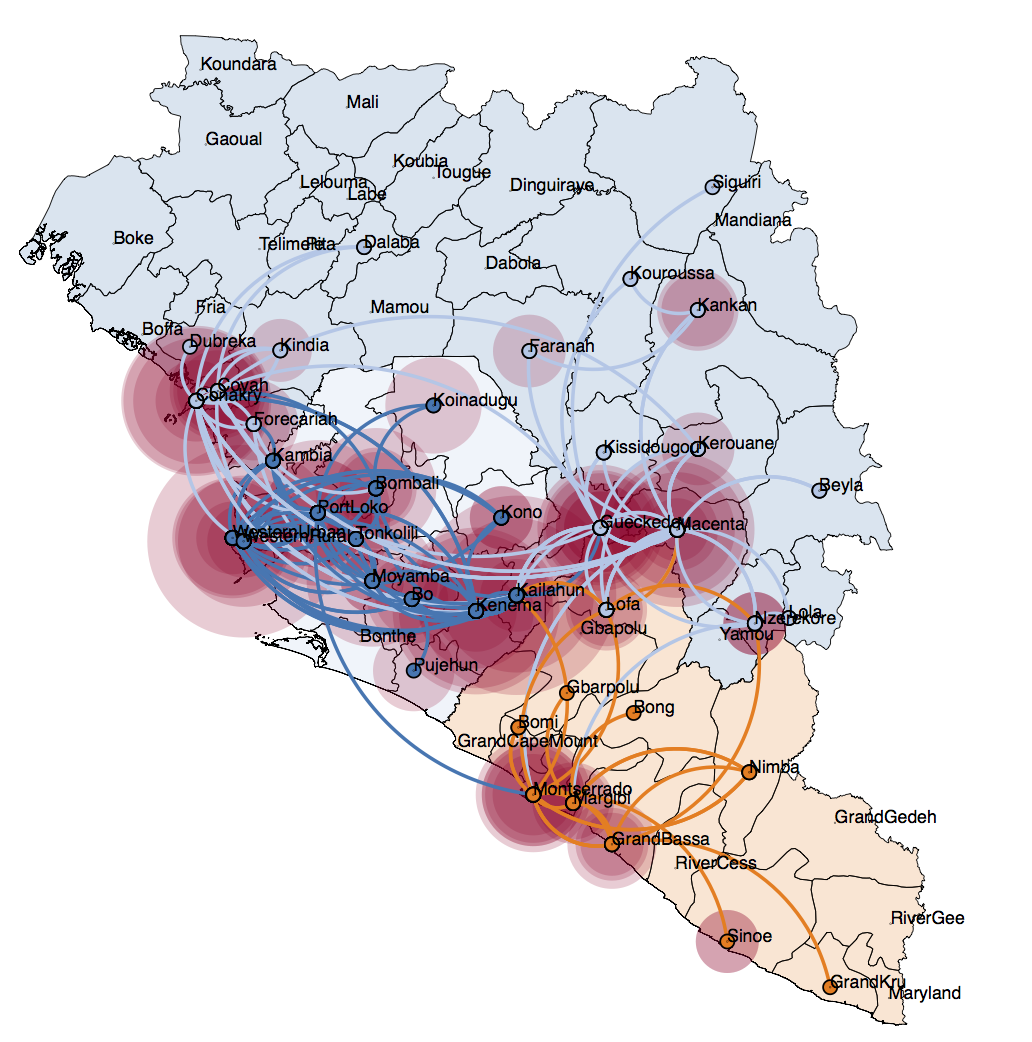
This package is sitting at the very end of a statistical analysis pipeline (BEAST), yet proved very popular. Fast forward a couple of years and I have been contracted to write a new release of it and I’m happy to say that the effort is well under way, and can be observed in the projects repository:
- https://github.com/fbielejec/spread.
Implementation
Due to the other obligations spread will remain a part-time effort, nonetheless it is my goal to release it as soon as possible (I guess by writing this I’m now held accountable).
For this reason I have chosen to re-use as much of the existing codebase as possible, resisting any big changes to the existing Java parsers. Instead these will be wrapped as a re-usable libspread Java library and called from the application code. Remaining parts of the system will be written in Clojure (backend services) and ClojureScript (user interfaces and vizualizations engine), becasue there are no better all-purpose languages in existence.
Spread has been planned as a web-application, the design document does not foresee it receiving a heavy load for long periods of time, rather to undergo spikes of high activity (during workshops or other research activity) in between which the system will remain idle for most of the time. In other words the system needs to be able to scale up and down horizontally in response to traffic increase or decrease.
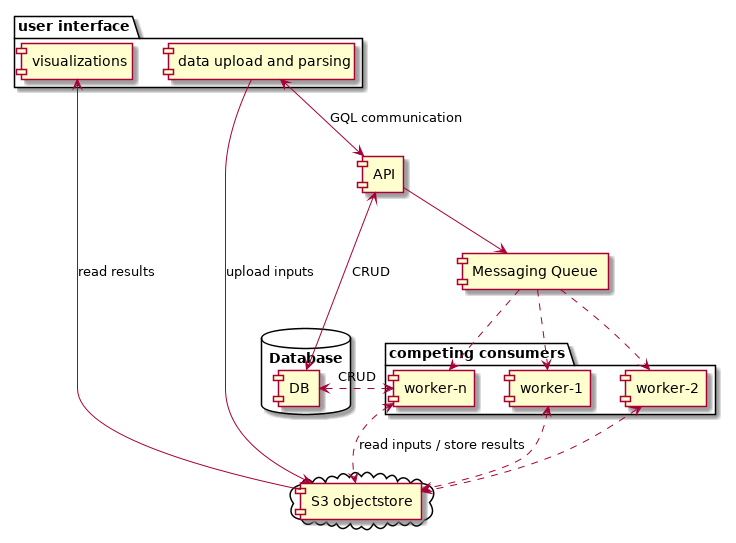
This will be achived by wrapping the computationally heavy parsers, calling the libspread library, as a fleet of single-threaded worker services, listening to a message queue. As messages get published to the queue, workers compete with one another to act on them, and the system is effectively load-balanced.
With the help of automated ECS auto-scaling rules, if the load increases more workers will be spawned when the queue of un-acked messages grows too large, and wind down if the system is idle.
For the client - backend communication I have opted to use GraphQL, again dictated by the practical reasons and code-reuse, as I have ample experience with the protocol carried from other projects. Persistance will be achived with a simple battle tested RDS (MySQL), and large input files from BEAST analysis will be uploaded directly from the client to and AWS S3 edge-server.
My talented brother will handle the UI/UX design and I was able to recruit the help of an awesome Clojure engineer, Juan who will likely implement the new visualization engine. Working in the Clojure space for a few years now, it sure feels like standing on the shoudlers of giants, and the project will make a heavy use of some awesome contributions to the tooling and the language itself:
- flow-storm debugger
- clj-kondo linter
- kaocha test runner
and many more.