CQRS and Event Sourcing
Introduction
In this blog post I will go over an architectural pattern which is a part of a broader spectrum of event based architectures. It is inspired by a StrangeLoop talk by Bobby Calderwood.
– TLDR
- CQRS involves splitting an application into two parts internally: the command side ordering the system to update state and the query side that gets the information without changing state.
- by decoupling the write and read paths, you can decouple the teams responsible for the implementation of the write and read logic.
Here is a summary of the Event Sourcing architecture:
- Commands represent user intentions
- Command Processors implement business logic and generate Events
- Events represents what happened and the final truth
- Other auxiliary services can be based on that
–
Companion repository can be found here: with-kafka.
CQRS and Event Sourcing: what’s in the name?
CQRS (Command/Query Responsibility Segregation) is a pattern which separates writes from the reads. In another words updating information uses a different model that reading that information, as opposed to the prevalent CRUD APIs, where the same model is being used throughout.
This separation of concerns fits many domains, albeit not all.
Note that the separation says nothing of how these two models should communicate - they may take entirely different paths in your system and run on a different hardware, or they may share the same database or even the same process.
The advantage is still the same : by separating reads from the writes you can evolve them in an independent manner.
NOTE
If you think that the GraphQL language concept bears some resemblance, you will be right, although I would argue that a semantic split between mutations and queries is not enough to constitute a real separation. Therefore depending on the details of a GraphQL based system we could (or not) be talking of fitting the description of CQRS, but the two are definitely compatible.
As already mentioned CQRS makes for a good fit with event-based architectures. The read/write model separation, which is the defining pillar of CQRS, allows to combine it with the other hero of this blogs entry title: the Event Sourcing pattern.
The fundamental idea behind this pattern is that every state-altering action in your system is recorded and stored, forever, in a time-ordered event log, rather than as an aggregate of all the changes as they were happening over time in a single database. Interesting enough databases are build on top of event logs, stored on disk therefore this concept has been touted as turning the database inside out by some of the greats.
The advantages of this approach are many-fold:
- There is now an audit log of everything that happened in the system at any given point in time.
- The aggregate views of your events (persisted in e.g. relational data-base) can be now recreated by replaying those events one-by-one.
- By constructing the materialized view of the data after the event is stored, we can change our interpretation of it in the future, or even construct different aggregates of those events and serve them concurrently to the clients.
Astute reader might observe that Event Sourcing defined above de facto must separate the read paths from the write paths, and that is correct. Therefore we could be talking of systems utilizing just the CQRS pattern, but not about systems utilizing Event Sourcing (ES) without some type of command and query separation (Greg Young mentions this in his talk).
Implementation
For some people, and I definitely subscribe to that camp, it is easier to be learning something by practicing it. Therefore after reading and researching some the vast literature on the topic (including but not limited to talks and write-ups by Martin Fowler, Greg Young, Martin Kleppmann) I decided to create a toy example (not built to scale nor painted) which implements some of these concepts.
Our domain will be a distributed calculator of sorts, fairly easy to reason about as well as assert the correctness of.
Below a simplified diagram of the system finds itself:
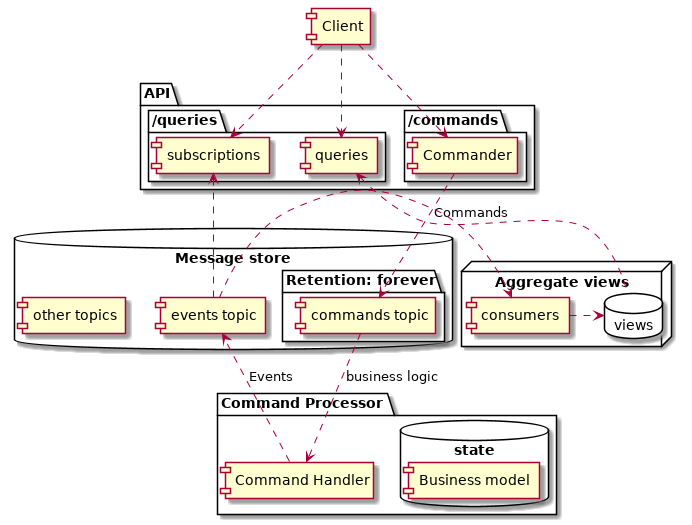
As an entry point we have a web service, exposing various endpoints. In the said application the API utilizes REST + HTTP/JSON, but it could just as easily be a (already mentioned) GraphQL API.
The Commander component is responsible for:
- Accepting commands / mutations (client intentions).
- Light schema validation.
- Authorization.
It writes Commands (intentions) to the dedicated Kafka topic. Our system supports two commands:
{"id" : <Uuid>,
"action" : "CreateValue,
"data" : {"value-id": <UUID>,
"value": <float>}
"timestamp" : <Timestamp>}
{"id" : <Uuid>,
"action" : "UpdateValue",
"data" : {"value-id": <UUID>,
"operation": <ADD / MULTIPLY>,
"value": <float>}
"timestamp" : <Timestamp>}
So we can create a value, add or multiply a value by some constant and retrieve it’s current aggregate value. An over-engineered calculator to put it simply.
The said commands topic is consumed by the Command Processor, a central component that:
- Implements business logic to validate Commands and check whether Events can be emitted.
- Sends Events to the events topic.
Events are state-affecting, and following the convention by Bobby Calderwood are using past tense for their action field, therefore a CreateValue Command, after being validated, will result in a ValueCreated Event being emitted, which carries the id of the Command that it derives from:
{"id" : <Uuid>,
"parent-id" : <Uuid>,
"action" : "ValueCreated",
"data" : {"value-id": <UUID>, "value": <float>}
"timestamp" : <Timestamp>}
The emitted events are consumed by what the diagram collectively refers to as the events consumers.
These micro-services are generating read optimized aggregate views of the data.
They are free to share the same database or each keep its own, they can subscribe to re-partitioned events or vanilla topic, write to and communicate using additional topics etc.
Main point being there is now an infinite number of ways to materialize a view of your data stored as events.
There is also a subscriptions component, where clients can listen to for the status of their commands.
Let’s see it in action
If you fork the repository there is a docker-compose.yml file at the root that you can use to get a Kafka broker and Zookeper started:
docker-compose -f docker-compose.yml up
Compile and boot the system. For
cargo run
Send your first command:
curl -d '{"value": 3}' -H "Content-Type: application/json" -X POST http://localhost:3030/values
Here are the logs from all the components, we can see the path that the message takes:
[2021-02-11T18:31:55Z INFO with_kafka::command_processor] Received command: CreateValue {
id: 7037a79d-7e6b-4969-9ea5-6d5c28605ac4,
data: Value {
value_id: d35e95f5-2a7a-4c31-8d28-2eb92643a154,
value: 3.0,
},
}, partition: 0, offset: 2, timestamp: CreateTime(1613068185765)
[2021-02-11T18:31:55Z INFO with_kafka::command_processor] validating command 7037a79d-7e6b-4969-9ea5-6d5c28605ac4 with data Value { value_id: d35e95f5-2a7a-4c31-8d28-2eb92643a154, value: 3.0 }
[2021-02-11T18:31:55Z INFO with_kafka::command_processor] Succesfully sent event ValueCreated {
id: ed94c20c-abe2-4d62-9cc7-904b266ed37a,
parent: 7037a79d-7e6b-4969-9ea5-6d5c28605ac4,
data: Value {
value_id: d35e95f5-2a7a-4c31-8d28-2eb92643a154,
value: 3.0,
},
} to topic events
[2021-02-11T18:31:55Z INFO with_kafka::materialized_view] Received event: ValueCreated {
id: ed94c20c-abe2-4d62-9cc7-904b266ed37a,
parent: 7037a79d-7e6b-4969-9ea5-6d5c28605ac4,
data: Value {
value_id: d35e95f5-2a7a-4c31-8d28-2eb92643a154,
value: 3.0,
},
}, partition: 0, offset: 7, timestamp: CreateTime(1613068315632)
Command Processor receives the command, validates it (checks if the value with this id does not already exist), and sends an Event, that is then processed by a view component.
So what happens if we send a MULTIPLY commands for a value that does not exist?
curl -d '{"operation": "MULTIPLY", "value": 3}' -H "Content-Type: application/json" -X PUT http://localhost:3030/values/ffffffff-ffff-ffff-ffff-ffffffffffff
Processor rejects it and no Event is generated:
[2021-02-11T18:36:42Z INFO with_kafka::command_processor] Received command: UpdateValue {
id: b694cc37-7657-4d27-97f5-e8f800ef05c4,
data: UpdateOperation {
value_id: ffffffff-ffff-ffff-ffff-ffffffffffff,
operation: MULTIPLY,
value: 3.0,
},
}, partition: 0, offset: 3, timestamp: CreateTime(1613068602444)
[2021-02-11T18:36:42Z INFO with_kafka::command_processor] validating command b694cc37-7657-4d27-97f5-e8f800ef05c4 with data UpdateOperation { value_id: ffffffff-ffff-ffff-ffff-ffffffffffff, operation: MULTIPLY, value: 3.0 }
[2021-02-11T18:36:42Z ERROR with_kafka::command_processor] command b694cc37-7657-4d27-97f5-e8f800ef05c4 rejected: value with id ffffffff-ffff-ffff-ffff-ffffffffffff does not exist
And if we now send a valid command and query for the value current state:
curl -d '{"operation": "MULTIPLY", "value": 3}' -H "Content-Type: application/json" -X PUT http://localhost:3030/values/d35e95f5-2a7a-4c31-8d28-2eb92643a154
curl -H "Content-Type: application/json" -X GET http://localhost:3030/values/d35e95f5-2a7a-4c31-8d28-2eb92643a154
#=> {"value_id":"d35e95f5-2a7a-4c31-8d28-2eb92643a154","value":9.0}
To demonstrate the replay-ability all state is kept in-memory and the Command Processor is configured to read from offset 0 (from the beginning of the topic). Therefore you can kill the process in which the components run and start it again to get the same state.
In practice, given that such a re-sync is single-threaded and potentially time consuming, one would rather let it persist its offset and state, so that it can start where it left off in case of a crash.
Potentially a copy could be created in a separate process, allowed to rebuild the Events log topic in a background and the system could switch to it with no visible downtime, to use a new, updated “state of the world”.
Some problems of this architecture
NOTE
A word of caution: This is the most subjective and opinionated part of this article, based on my understanding of the topic (and I have been wrong in the past). It should therefore be taken with a grain of salt.
The strengths of the architecture are also constituting some of it’s weaknesses.
Having a single thread and synchronously processing all incoming commands is a nice property, easy to reason about, albeit it does not scale. The unit of concurrency in Kafka is a partition, with multiple consumers able to consume and process topic partitions in parallel.
But how do we partition the commands or the derived events topic, without loosing the ever-important time ordering?
The most important rule is that any events that need to stay in a fixed order must go in the same topic, and they must also use the same partitioning key – Martin Kleppmann
If your domain allows for it, you can partition commands topic, even send every command type (called action in the demo) to a different partition.
A good example would be e.g. telemetry data coming from independent sensors.
If you cannot do that, the second option is to set an arbitrary number of partitions (you can always re-partition the topic later on) and distribute the commands uniformly in a round-robin way. Naturally you cannot guarantee at this point that the consumers subscribing to these topic partition lists will receive them in the same order as they were sent, which may or may not be a problem, depending on the domain you are working with.
You might be tempted to use the timestamps that are included with the Kafka messages, either as part of the schema or in the meta-data and sort the commands in-memory. Don’t do this :)
(…) in a stream process, timestamps are not enough: if you get an event with a certain timestamp, you don’t know whether you still need to wait for some previous event with a lower timestamp, or if all previous events have arrived and you’re ready to process the event. – Martin Kleppmann
What options does it leave you with? Well, you can simply ignore relations in your data, and store it “as-is”, or rather “as-arrives”. If we are talking about using relational database as a storage, this would be akin to not using foreign keys.
Naturally, that would mean that you do not care, or that you only care eventually about the relational consistency of your data.
Consider a social network example - can you afford to process a UserMessageSend commands before UserAccountCreate?
What if your processor rejects or throws when processing the latter but not the former?
You end up with a corrupted view of your data, but perhaps it is not a deal-breaker, and the fact that you can replay the history at will is enough of a pro that the cons do not deter you.
To sum up, if your domain calls for a relational consistency of the data, or you cannot afford it to be eventually consistent than this pattern might not be a good fit for your domain.